
Effective MLOps is the concept we preach at ML Architects Basel to democratize MLOps and make it accessible to non-high-tech companies and businesses. In a previous blog post we shared our scope and framework of this innovative approach. In this piece, Effective MLOps in action, we aim to demonstrate the technical implementation dimension of Effective MLOps, based on open source-technologies for an end-to-end ML workflow.
But before diving deeply into the technical implementation of Effective MLOps, we think it is vital to understand the context of its application and why it is the right approach to have when dealing with ML projects.
MLOps Context
Machine learning (ML) projects are complex and need profound knowledge in various areas such as data science, computer science, mathematics, business domain knowledge, etc. Different teams are involved in different parts of a ML project to design, produce, deploy and maintain ML software such as data engineers, data scientists, ML engineers, software developers, site reliability engineers, DevOps engineers etc. These projects require diverse tools and workflows besides being very complex, hard to predict, to test, explain and improve.
In order to successfully manage investments in ML projects, operationalizing the models and implementing systems, including data, model and code pipelines, to not only develop, but also operate them is crucial. Thus, there is a need for an end-to-end process for building, training, deploying and monitoring Machine Learning systems. This process should leverage automation and quality assurance to create a reliable and repeatable pipeline to deploy and maintain ML software in production especially since ML applications operate in a highly dynamic environment where data, features, algorithms and parameters are continuously changing.
In terms of Software Engineering, the DevOps approach has shown its efficiency in providing continuous delivery and high software quality. However, we cannot duplicate DevOps principles as they are, when dealing with ML projects as they present different challenges and a more complex workflow. A robust ML architecture has to cope with new requirements or changing conditions to facilitate and harden the integration of new data, features and configurations according to new business and technical requirements. It has to ensure traceability of data, code and configurations used to build ML models. This is where Effective MLOps should be leveraged. Let’s see how we do that in a concrete use case.
Effective MLOps in Action: The Use Case
Breast cancer is the most frequently diagnosed life-threatening cancer worldwide (12.3% in 2018) [5]. Machine Learning has been heavily applied in life science and health to predict and prevent diseases. For the purpose of this demonstration, we will rely on a dataset provided by the University of California Irvine. It has been created in the early nineties and we can easily find clinical measurements, such as clump thickness, uniformity of cell size and shape, marginal adhesion, single epithelial cell size, bare nuclei, bland chromatin, normal nucleoli and mitoses. We will create a binary ML classifier while applying our MLOps approach to present our unified solution for an end-to-end process for building, training, deploying and monitoring a ML project.
Effective MLOps in Action: The Technical Setup
Our solution aims to improve each point listed below and tie them up together to provide an easy and reliable solution addressing the question of how to implement continuous delivery and observability for a complex ML project:
Data Versioning
Most machine learning methods deal with data that often comes from different sources like files, streaming, etc. In order to track data that we feed to our system and we have to provide a versioning system that takes snapshots of the training input dataset. For that, we propose to use GitLab, DVC (Data Science Version Control) and AWS S3 bucket to manage all data sources. All data is stored in the S3 bucket and meta files generated by DVC are stored in the git repository where we keep a link to the remote repository. The used dataset contains information regarding breast cancer as shown in Figure 1.

Model Tracking
We used common classification algorithms that can predict if the patient has breast cancer using the available data. For this proof-of-concept, we picked up a logistic regression and KNeighbors classifier to build the model. The idea is to build a system that can easily be improved by adding new features, updating parameters or adding new data. We will not go deeper in details regarding algorithms’ selection and optimization as we aim to focus on the continuous delivery for ML aspect. We used Python as a programming language, Scikit-learn as ML library and Jupyter notebook as a development environment. We used MLflow, which is an open-source platform for tracking experiments. MLflow provides several other key functionalities such as tracking hyper parameters, artefacts, model registration and management, and experiment execution triggers. We prepared an AWS EC2 instance that hosts the MLflow application which is connected to an AWS S3 bucket. Through the MLflow web app, we can capture, visualize and manually compare the produced model as shown in Figure 2.
As we are in an ML application, automating all of the above is key. To do that, we wrote a Python script that compares the trained models and selects the most accurate one based on metrics of your choice. For this example, we compare the accuracy of each model. This script is triggered by GitLab every time a new experiment is created.
Using the GitLab CI/CD tool, we started by defining the train stage as shown in Figure 3, where we install dependencies in the Python docker image, pull the latest version of data using DVC and finally build and select the most accurate model. The latter will be added to the GitLab artefacts to be accessible later on to the next stages.

API
Once the model is created, we used the Flask framework to provide a RESTful API which we wrapped up in a docker image and pushed it to an AWS Elastic Container Registry (ECR).
Web App (optional)
To be able to interact with the backend in real time in a user-friendly way, we created and dockerized an Angular web application that we stored and also pushed to an AWS ECR. It is ready to be deployed.
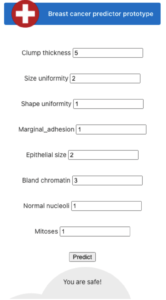
Deployment
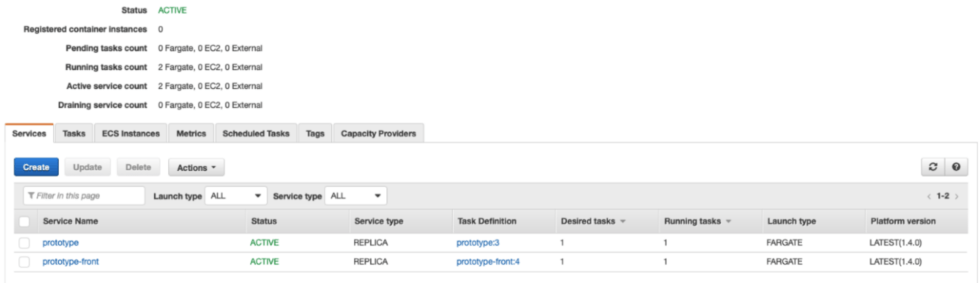
At this stage, two docker images are made available to our ECR, the web app and the machine learning model integrated into a Flask API. We used AWS Elastic Container Service (ECS), as shown in figure 5, to run them on different ports and configured a Load Balancer to which we assign a static IP address through Elastic IP. A task definition file has to be defined to automate the execution of services. Depending on the project, the dataset and further requirements, the deployment stage may be trickier, and a pre-production/testing stage could be added to the pipeline before the deployment phase.
Continuous Integration / Continuous Deployment (CI/CD)
CIMost of the previous steps should be tied up and automated to chain all stages. A set of tests are implemented to validate data, check model quality and test project’s components. We added two new stages to gitlab-ci.yml, as presented in figure 6, where we specify the different steps and scripts to execute once a commit is triggered.

In Figure 7, the publish stage consists of building docker images using the docker in docker service to build and push the image to the ECR repository using the AWS CLI. Once this stage is successfully completed, the deploy stage will register the predefined task definition and run it in a Fargate AWS cluster. A rollback process should be considered to address poor model performance.

Monitoring and Observability
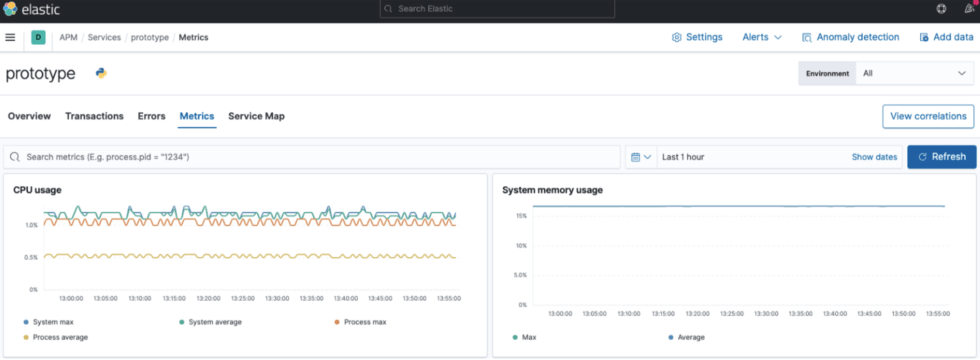
Now that our application is running, we need to keep a close eye on how it is performing using Monitoring and Observability technologies. For this case, we use the ELK stack (Elastic, Logstash and Kibana) to monitor our application during run-time. We connect the Cloudwatch logs to our Elasticsearch located on EC2 instance. Then we create an APM agent to visualize some metrics regarding both our model and our application performance as shown in Figure 8.
Effective MLOps: Technical Architecture Overview
Now that we covered, one at a time, the different phases of deploying an end-to-end ML application starting from data versioning until monitoring and observability, let us have a look at how our Effective MLOPs technical architecture looks like overall.
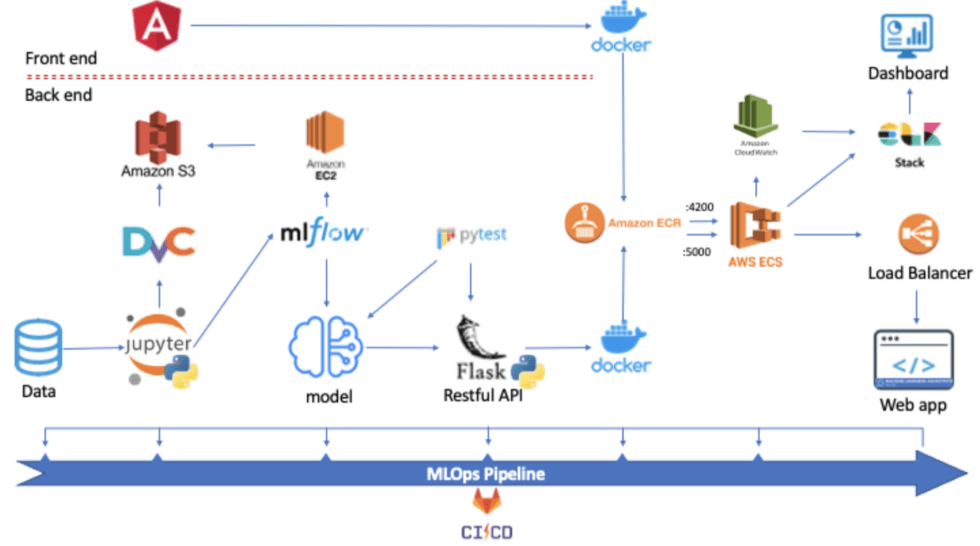
For the purpose of illustrating our approach and the needed capabilities in a simple manner, we used a set of open-source software and AWS for deployment. This solution provides a low-cost implementation and full visibility on the code base. Nevertheless, commercial technologies and enterprise-grade platforms like Databricks could be an alternative for a faster implementation, collaboration and customer support. For large enterprises, the latter solution might have more benefits as it bypasses some tricky configurations and provides a compact platform.
As for AWS platform, we can very well adapt this workflow to Google Cloud Platform, Microsoft Azure or other hosting solutions.
In this article we have tried to illustrate how we build, maintain and operate a machine learning software from data versioning to monitoring in production. We also demonstrated how we can continuously improve and automate an end-to-end ML implementation. This approach is aiming to optimize maintenance, traceability and make projects reproducible, addressing not only the technology dimension of our Effective MLOps framework. It is suited for Agile methodologies and offers a sophisticated pipeline that breaks down barriers between different teams involved in a ML project, thereby also addressing challenges regarding culture and operating model.
Footnotes and References
- MLOps: Continuous delivery and automation pipelines in machine learning (Google – 2020): link
- MLOps: Continuous Delivery for Machine Learning on AWS (Amazon – 2020): link
- Continuous Delivery for Machine Learning (Danilo Sato, Arif Wider, Christoph Windheuser – 2019): link
- Predict-Breast-Cancer-Logistic_Regression Repository: link
- Worldwide cancer data: link
