
Introduction
In the rapidly evolving world of AI, agents powered by Large-Language Models (LLMs) unlock everything from conversational support to automated content creation. Yet deploying them reliably in production remains a challenge. In this tutorial, we'll show how to stand up an LLM-driven agent on Azure AKS; every step maps 1-for-1 to AWS or GCP if that's your stack.
This tutorial is part of our AI-Engineering series and complements our earlier post on Introduction to AI Engineering. .
Prerequisites
To follow along, you should be familiar with:
Azure services (Key Vault, Application Insights, Log Analytics, AKS)
We'll deploy everything on Azure, but identical concepts apply to other clouds.
Kubernetes concepts and management
AKS handles scaling and rollout. Alternatives such as Docker Swarm or Mesos work too, but the Kubernetes ecosystem makes life easier.
Terraform for Infrastructure-as-Code
Terraform lets us declare-not-click our infrastructure and reuse the code on any cloud.
Helm Charts
Helm bundles our Kubernetes resources into versioned, repeatable releases.
Overview of the Stack
We'll deploy our agent on an Azure AKS cluster and configure logging, tracing, and CI/CD via Helm Charts.
Features of our agent
The agent will be able to:
- Answer questions about our website
- Draft e-mails
- Convert currencies on the fly
- Gracefully respond to off-topic queries
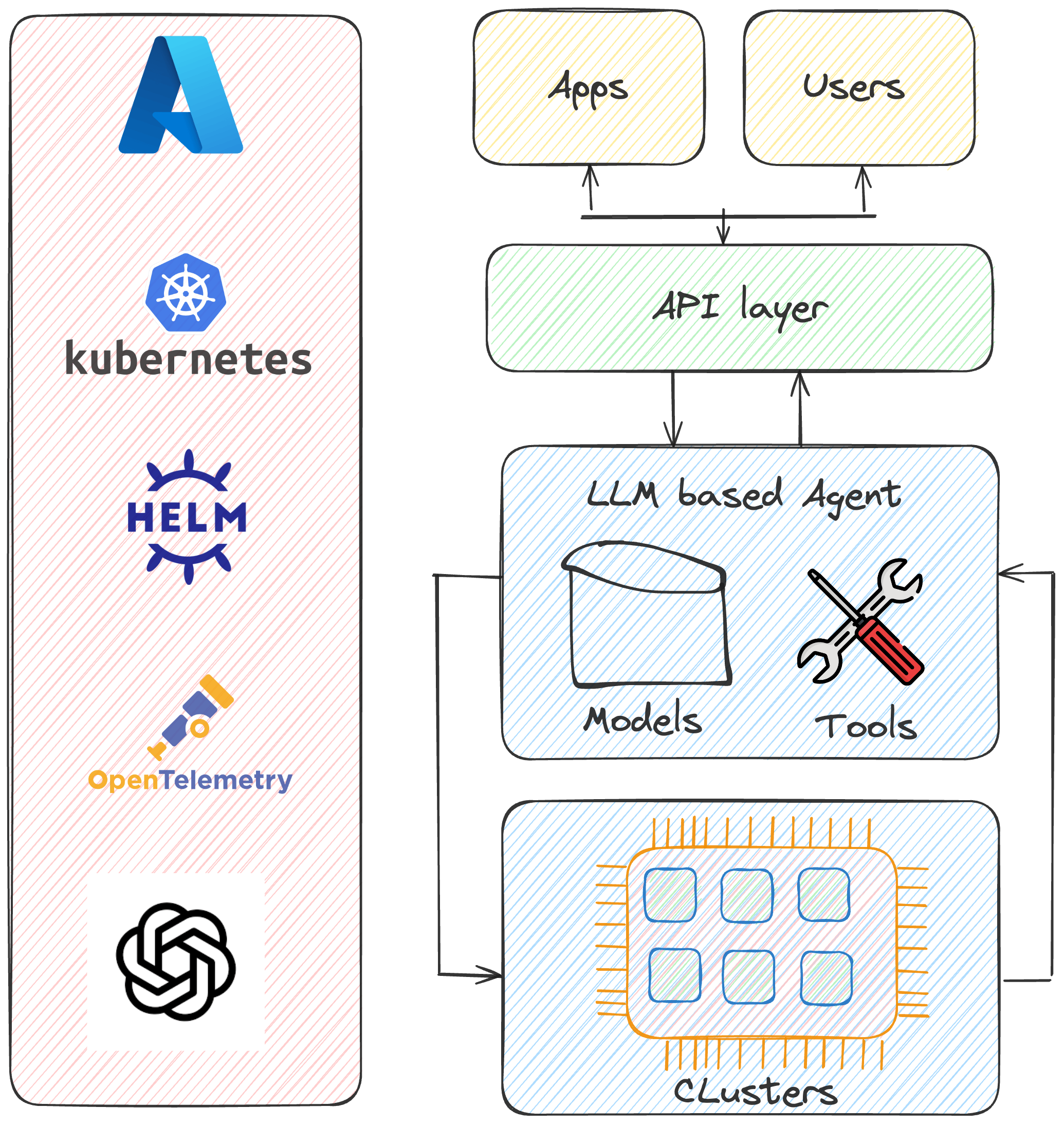
Components of our agent
The agent relies on four building blocks:
- Data pipeline (crawler → embeddings → ChromaDB → Azure): This ingests the relevant subsites on our website
- Agent tools (retriever, e-mail draft/send): This enables the agent to use functionality such as writing an email, and retrieving information about our website
- LLM planner: After a query from the user arrives, our agent plans the substeps it needs to take to answer the query. Furthermore, it plans whether it should use any tools to answer the query or if it can answer without any tool usage.
- Short-term memory: To remember the tools that the agent has already used and the conversation that has already taken place
- An API that lets any frontend interact with the agent.
Concretely, our agents' architecture will look like this:
Step-by-Step Tutorial
Step 1 – Set up AKS, Log Analytics & Container Registry
We create the cluster, enable logging, and push a private registry; RBAC permissions let AKS pull the image. We set up the whole infrastructure using Terraform, which spins up the cluster, Application Insights, the Azure Container Registry, and the key vault. Here is a snippet, that sets up the infrastructure:
data "azurerm_key_vault" "mlab_kv" {
name = "kv-mlab-dev"
resource_group_name = data.azurerm_resource_group.mlab_rg.name
}
resource "azurerm_kubernetes_cluster" "mlab_aks" {
name = "mlab-aks-cluster"
location = data.azurerm_resource_group.mlab_rg.location
resource_group_name = data.azurerm_resource_group.mlab_rg.name
dns_prefix = "mlab-aks"
default_node_pool {
name = "default"
node_count = 2
vm_size = "Standard_DS2_v2"
}
identity {
type = "SystemAssigned"
}
tags = {
environment = "dev"
}
}
Step 2 – Deploy the agent
AKS handles container orchestration, auto-scaling, and load-balancing. We choose VM sizes optimised for our model's GPU and memory needs. For this example, we chose an instance size that is free, as we are currently operating Azure on a free license.
Step 3 – Integrate OpenAI models
Supply your OpenAI API key (or Azure OpenAI endpoint) and update it in the Azure key vault secrets
Step 4 – Add observability with OpenTelemetry and Opik
Reliability starts with instrumenting the code itself. The Python snippet below wires OpenTelemetry into our agent so that every prompt, tool call, and model token is traced, logged, and counted. A lightweight Collector sidecar then streams those signals to Azure:
- Traces – each request becomes a trace with spans for plan-build → tool-call → LLM-compose, enabling slow-path replay in Application Insights.
- Logs – structured JSON (prompt, response, token count) land in Log Analytics for ad-hoc search.
from opentelemetry.instrumentation.logging import LoggingInstrumentor
from my_agent.utils import init_logger # your helper
AZURE_CONNECTION_STRING = os.getenv("AZURE_MONITOR_CONNECTION_STRING")
# ---------- Tracing ----------
resource = Resource(attributes={SERVICE_NAME: "mlab-agent"})
trace.set_tracer_provider(TracerProvider(resource=resource))
tracer_provider = trace.get_tracer_provider()
if AZURE_CONNECTION_STRING:
from azure.monitor.opentelemetry.exporter import AzureMonitorTraceExporter
trace_exporter = AzureMonitorTraceExporter(
connection_string=AZURE_CONNECTION_STRING
)
tracer_provider.add_span_processor(BatchSpanProcessor(trace_exporter))
print("🔗 Azure Monitor trace exporter enabled.")
else:
tracer_provider.add_span_processor(
SimpleSpanProcessor(ConsoleSpanExporter())
)
print("🖥️ Console span exporter enabled for local dev.")
# ---------- Logging ----------
if AZURE_CONNECTION_STRING:
from azure.monitor.opentelemetry.exporter import AzureMonitorLogExporter
log_exporter = AzureMonitorLogExporter(
connection_string=AZURE_CONNECTION_STRING
)
otel_handler = LoggingHandler(level=logging.INFO)
provider = LoggerProvider()
provider.add_log_record_processor(BatchLogRecordProcessor(log_exporter))
With this in place, you can open Application Insights and:
- Expand a trace to see every agent decision step → was the Currency-Converter tool slow, or did the LLM skip it?
- Create an alert when P95 plan-build latency exceeds 500 ms.
INFO:mlab-agent:🧾 LLM raw response: {
"requires_tools": true,
"direct_response": null,
"thought": "I need to draft an email to Sammer Puran regarding a meeting about MLOps. I'll use the write_email_draft_tool to create the email draft.",
"plan": [
"Use the write_email_draft_tool to draft an email to Sammer Puran.",
"Include a subject line and a message body that clearly states the purpose of the meeting."
],
"tool_calls": [
{
"tool": "write_email_draft_tool",
"args": {
"recipient": "Sammer Puran",
"recipient_email": "sammer.puran@ml-architects.ch",
"subject": "Request for Meeting Regarding MLOps",
"message_body": "Dear Sammer,\n\nI hope this message finds you well. I would like to schedule a meeting to discuss MLOps and explore potential collaboration opportunities.\n\nPlease let me know your available times.\n\nBest regards,\n\n[Your Name]"
}
}
]
}
Conclusion
Congratulations, you have a successful, simple agent running that is accessible via an API. As you have seen, a reliable agent requires a solid backbone—elastic compute, IaC, observability, and CI/CD. With this stack, you can iterate safely and scale confidently. In our next sessions, we will dive deeper into testing and evaluation for agents, evaluations of different frameworks to implement agents a deeper dive into monitoring and multi-agent systems. Questions or feedback? Contact us!
Machine Learning Architects Basel
Machine Learning Architects Basel (MLAB) is part of the Swiss Digital Network . We help customers deploy and scale data & AI products.