
Introduction
Are you eager to find out how you can implement data products with a ‘Digital Highway’ approach powered by quality assurance and pipelining best practices? Do you want to know how to do this technically?
In this hands-on guide, we demonstrate how to structure a GitLab CI pipeline to implement data as a product solution within the data mesh domain and apply data contracts and data unit tests using dbt (Data Build Tool) across different teams. If you want an introduction to data mesh, data as a product, data domains, data contracts, and an explanation of how we apply our Digital Highway approach you can read our previous blogpost.
The following illustration provides a high-level overview of a data mesh architecture:
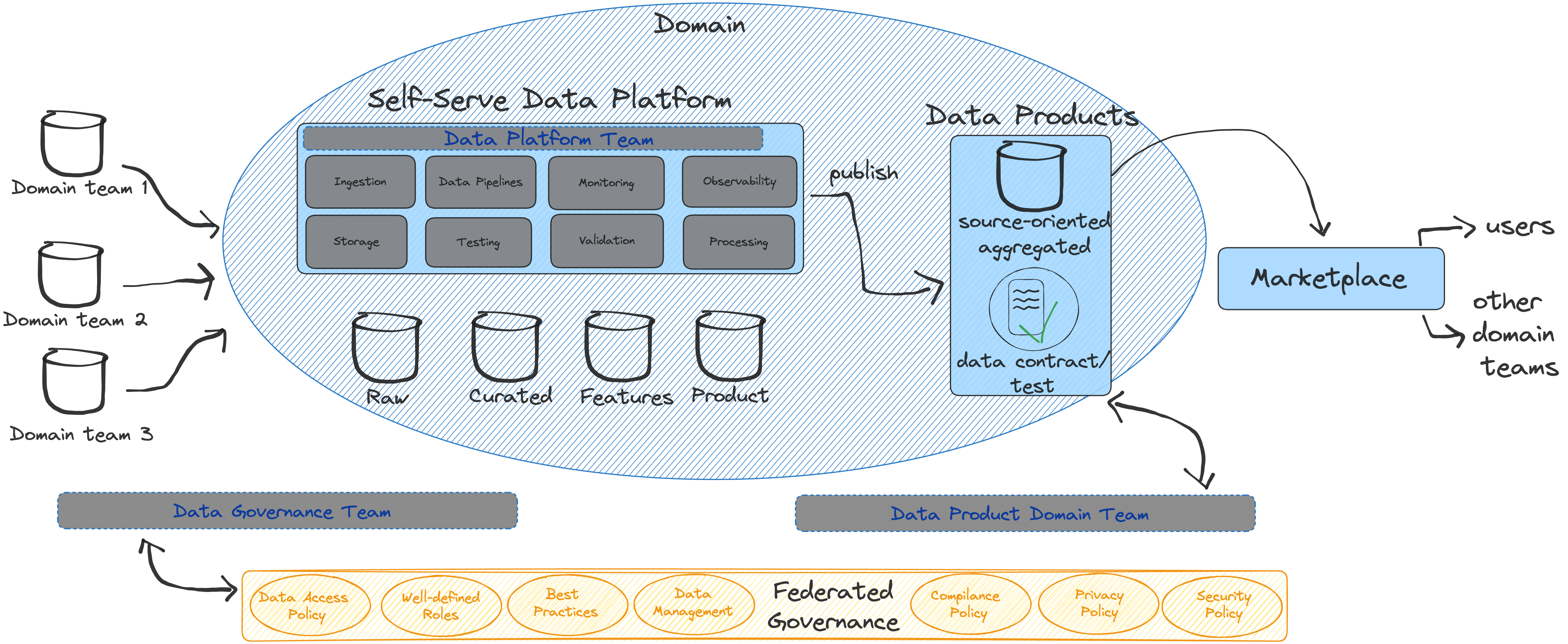
In short, the following approach ensures that the "data as a product" concept is applied to all integrated teams with a managed, tested centralized solution in a repeatable, reliable, and automated process.
Let’s imagine an organization that would like to incorporate data mesh into its daily workflow. In this article, we will not discuss the details of domain ownership, self-service data infrastructure platforms, and federated governance because these depend mostly on the organization's structure.
Based on federated governance, we aim to internally apply data contracts and data tests for all the different teams. We maintain a master data contract repository where the data contract definitions and all associated tests reside. By leveraging GitLab CI, we can automate the process of applying these DBT run files into the different teams' data pipelines, ensuring consistent application of data contracts and tests across the teams.
Concept Explanation
Let's consider an organization with several business units: marketing, market segment, and sales. Each site needs to produce data in a consistent way (same set of tables, data types, schemas, etc.) for the downstream centralized ML team or other analytics needs.
Marketing Unit
They generate data on customer purchases, including customer IDs, purchase dates, product IDs, sales amounts, campaign data, such as campaign IDs, and customer engagement metrics.
Market Segment Unit
They collect the same data as the marketing branch plus conversion rates.
Sales Unit
They consolidate additional financial data, including customer payments, refunds, and revenue breakdowns.
Requirements from the Machine Learning Team
- Consistent Data Presentation: All teams must present data with standardized formats and field names to facilitate easy joins and integration.
- Joinable Tables: Data should be structured to enable seamless joins based on common keys like customer_id.
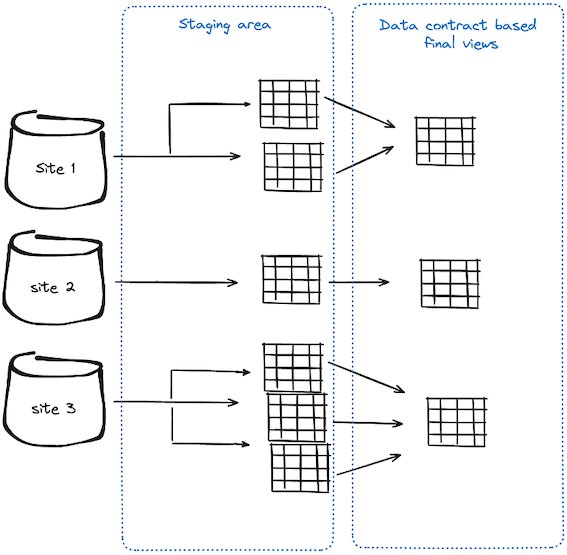
With the above-mentioned approach, we can ensure:
- Consistency: Data contracts standardize data formats and schemas across teams, making integration seamless.
- Enhanced Data Quality: Automated testing and validation ensure high-quality, reliable data.
- Collaboration: Clear data definitions and requirements help different teams work together more effectively.
- Scalability: A unified approach to data handling makes it easier to onboard new teams and adapt to evolving requirements.
Benefits of Data Contracts
Data contracts streamline the daily work of the downstream teams by reducing the time spent on data cleaning and preparation, allowing them to focus more on analysis and insights. They minimize errors and inconsistencies, leading to more accurate and reliable results. Clear data contracts facilitate quicker onboarding for new team members, as expectations and standards are well-documented. Additionally, they enable more efficient troubleshooting and debugging, as data issues can be quickly traced back to their source.
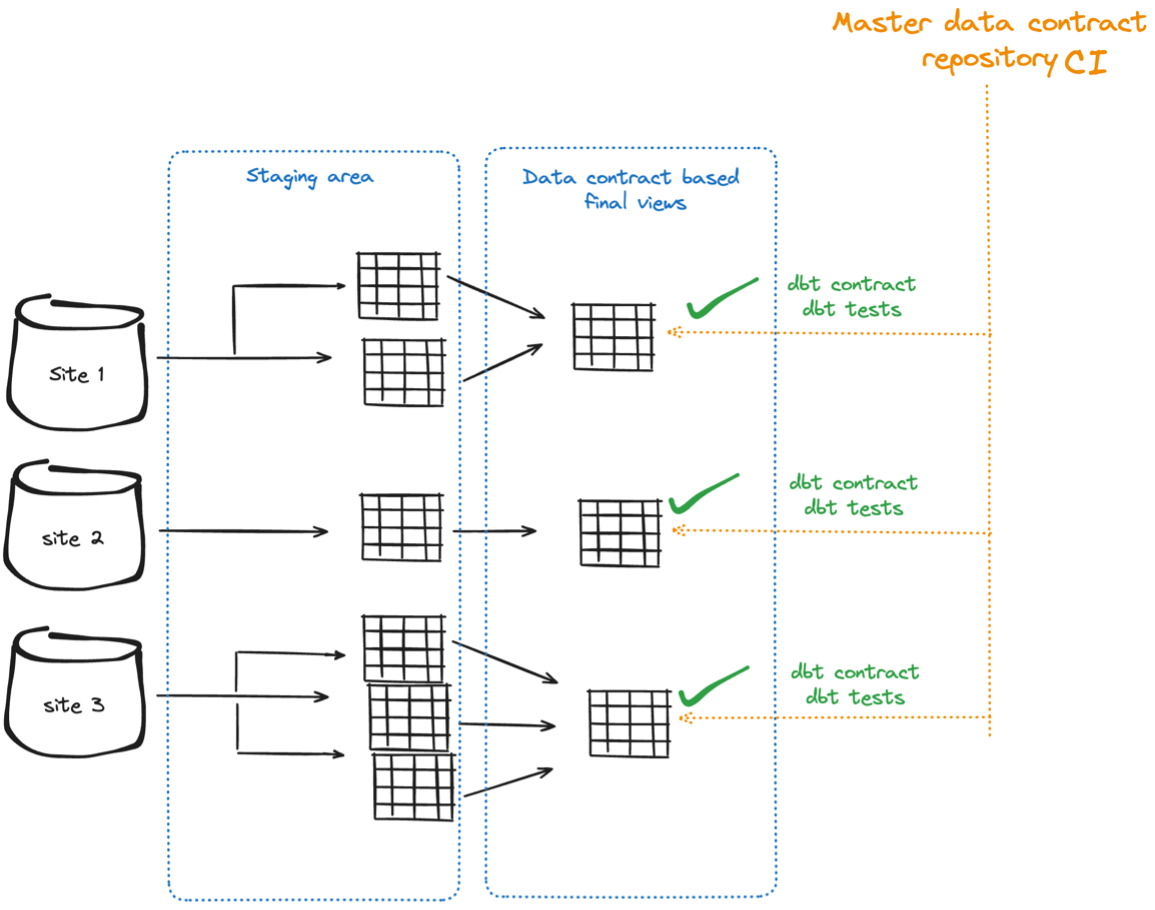
With a, let’s call it, Master Data Contract Repository, we can define and enforce consistent schemas and data quality rules.
By automating the GitLab CI pipeline to apply these contracts and tests, we can apply DataOps best practices and ensure compliance before the data is available to downstream teams.
Implementation
Using a centralized template in the GitLab CI configuration of the master data contract repository helps to move to a more standardized solution. We define the stages necessary to apply data contract checks and tests for various teams. This approach enables us to implement CI-based data contracts and data tests efficiently, ensuring that our master data contracts and tests are applied uniformly to all teams.
The master data contract is a DBT project with all the required definitions and files. In the models folder, we define the data contract and tests that will be applied to all business units.
models:
- name: s1_analytic_contract_model
description: Model with enforced contract for site1
config:
contract:
enforced: true
tags: ["contract_based"]
columns:
- name: product_id
data_type: integer
data_tests:
- not_null
- name: product_name
data_type: character varying(100)
- name: product_code
data_type: character varying(100)
- name: form
data_type: character varying(50)
data_tests:
- accepted_values:
values: ['Form1', 'Form2', 'Form3']
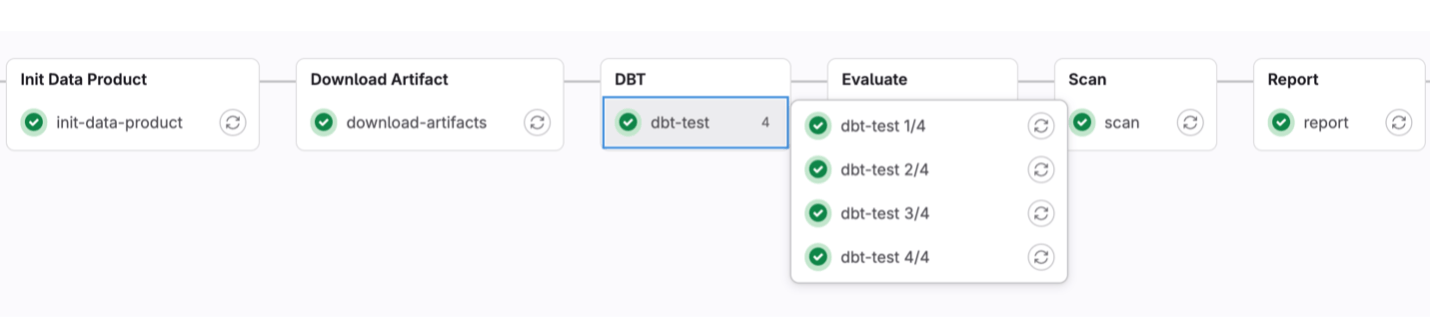
GitLab CI Integration
The repository contains a gitlab-ci-template.yml file that describes the different stages for applying the DBT-based contract and unit tests.
dbt-test 1/4:
stage: DBT
extends:
- .artifact-commands
script:
- python artifact/dbt_contract.py
dependencies:
- download-artifacts
dbt-test 2/4:
stage: DBT
extends:
- .artifact-commands
script:
- python artifact/dbt_test.py
dependencies:
- download-artifacts
dbt-test 3/4:
stage: DBT
extends:
- .artifact-commands
script:
- python artifact/dbt_cleanup.py
dependencies:
- download-artifacts
The downstream teams must reference this template file in their gitlab-ci.yml file. Of course, they can set up additional test cases, but the contract and unit tests are mandatory for success.
Applying DBT Packages and Tests
To start the tests, we need to implement the built-in DBT solution called “packages.” DBT packages are reusable modules that encapsulate data transformations to enforce data contracts across different projects. Every site has to have a packages.yml file that defines the git repository where the master data contract sits.
packages:
- git: "https://{{env_var('DEPLOY_TOKEN_USER')}}:{{env_var('DEPLOY_TOKEN_PASSWORD')}}@gitlab.com/machine-learning-architects-basel/master_data_contract.git"
revision: main
Not to forget that the dbt test commands are in the master repository as well:
dbt test–models tag:contract_based --project-dir data_product/dbt_project --profiles-dir data_product
So, the business units just need to have this reference in their DBT-based packages.yml file and Gitlab file, where they reference the master data contract repository’s template-ci.yml file with the include command.
include:
- project: 'machine-learning-architects-basel/master_data_contract'
file: '/.gitlab-ci-template.yml'
stages:
- Lint
- Deploy
- Init Data Product
- Download Artifact
- DBT
- Evaluate
- Scan
- Report
Accelerate Data Product Building
Supporting the establishment of standardized methodologies. Implement modular, reusable components and templates within DBT and leverage CI pipelines to automate data contract and unit tests, reducing manual effort and speeding up development cycles.
Standardize Data Product Building
Establish a set of standards for DBT projects, data contracts, and tests and enforce them in an automated manner. Building a "master data contract" repository can standardize data contracts across business units. Enforce this data contract with a built-in step in the CI pipeline.
Ensure Data Quality
With data transformation tools such as DBT, we can support setting up standardized data quality checks using built-in solutions from dbt-utils. Incorporate automated data quality checks within CI pipelines using DBT tests and other validation tools, ensuring that any data quality issues are identified and resolved early in the development process. By ensuring that data from the business unit teams is standardized and consistently formatted, the ML team can efficiently use this data to train models, derive insights, and drive decision-making processes! If any team violates the data contract, the pipeline fails and the change is not applied to the production system.
Take-aways
In the example of our organization with the different business units, applying the "data as a product" concept with data contracts and tests has multiple benefits:
Consistency:
The organization ensures that all business units produce data in standardized formats and schemas. This improves data integration and usage by the downstream ML team, enhancing overall data reliability and usability.
Enhanced Data Quality:
Automated data quality checks and validations through DBT and CI pipelines ensure that high-quality, reliable data is consistently delivered. This points out possible errors in the early development phase and reduces inconsistencies, leading to more accurate insights and decision-making.
Collaboration:
Clear and standardized data definitions and requirements ensure improved collaboration among different teams. Each unit understands the data expectations and can work towards a unified goal, streamlining the data pipeline and reducing friction.
Scalability:
The approach is scalable, making it easy to onboard new teams or expand existing ones. New business units can quickly align with the established data standards and processes, ensuring a smooth integration into the organization's data ecosystem.
Efficiency:
By automating data contracts and unit tests, the organization reduces manual effort and accelerates the development cycle. Teams can focus more on deriving insights and less on data preparation and troubleshooting, leading to faster and more efficient operations.
Overall, this structured approach to implementing data as a product ensures that the organization can maintain a consistent, high-quality, and scalable data environment, supporting the downstream ML team or any other teams in training models, deriving insights, and driving informed decision-making processes.
If you want to learn more about applying data contracts and data tests, feel free to contact us with any questions!
Machine Learning Architects Basel
Machine Learning Architects Basel (MLAB) is a member of the Swiss Digital Network (SDN). With several years of experience and a team of experts, we support our customers in implementing data mesh, data contracts, and the "data as a product" approach. Our pioneering solution patterns, including the Digital Highway for End-to-End Machine Learning & Systems and our expertise in Data Reliability Engineering have led us to develop robust frameworks and reference models for DataOps, Machine Learning, MLOps, DevOps, SRE, and agile transformations. This unique blend of knowledge and experience positions us to help organizations implement reliable data solutions.