
Artificial intelligence (AI) and machine learning (ML) are key drivers of digital transformations in today's organizations. Many companies want to benefit from AI and ML in hopes of turning data into value. As Venturebeat points out however, «Artificial intelligence (AI) in the lab is one thing; in the real world, it’s another. Many AI models fail to yield reliable results when deployed. Others start well, but then results erode, leaving their owners frustrated. Many businesses do not get the return on AI they expect». The Venturebeat article then explains the importance of continuous data quality management and MLOps (machine learning development and operations). The question remains how to successfully implement an end-to-end approach for reliable and continuous machine learning delivery and operations.
In this blog post, we present our blueprint for a digital highway for MLOps to address that question and illustrate how organizations can generate sustainable value by building and running reliable machine learning solutions. Figure 1 shows the overview version of our digital highway. Read the blog post to find out more and to see a more detailed illustration (or skip right there)!
- Machine Learning and DevOps as key drivers of digital transformation.
- How maximum and sustainable value is generated through operationalization, MLOps and continuous delivery.
- A detailed break-down and illustration of our digital highway for reliable and continuous machine learning delivery and operations.
- References to further important aspects, such as technologies, culture and operating model, and a holistic maturity model.
- Machine Learning is changing the world
- MLOps: Generating value from ML
- Developing the blueprint for a digital highway
- The Machine Learning lifecycle
- Data pipeline
- Model pipeline
- Application pipeline and release strategy
- Production infrastructure
- Observability and incident management
- Site Reliability Engineering (SRE) for MLOps
- Code & Artifact stores
- AIOps
- Testing and Quality gates
- Manual exploration and experimentation
- Roles and cross-functional collaboration in MLOps
- The pillars which complete the blueprint
- Our detailed blueprint
- Technology tools and solutions
- Culture and operating Model
- Machine Learning Architects Basel
Machine Learning is changing the world
Machine learning (ML) has taken the world by storm. It touches many aspects of life in some way, often without being noticed. Examples include recommendation systems (e.g., Amazon's algorithm), predictive typing (e.g., Microsoft's algorithm), playing games (e.g., DeepMind’s AlphaGo), and natural language processing (e.g., Google Translate).
Many companies now want to follow these global leaders and leverage machine learning capabilities to address issues they are facing. Unfortunately, it is rarely as simple as just training and integrating an ML model into their existing software architecture and then "forgetting" about it. The illustration in Figure 2 tries to capture this sentiment. Most of the value of AI for companies (as opposed to researchers) lies in its operationalization. Models need to be configured, tested, deployed, monitored, and updated. A model's performance needs to be tracked (see also our observability blog post), and when the performance degrades and/or new data is collected the model needs to be updated.
MLOps: Generating value from ML
Even though model building takes a prominent and "cool" place in the lifecycle of a machine learning project, ML code only takes up a tiny part of mature ML systems (Figure 3). MLOps builds on top of DevOps and deals not only with ML code but also with all the surrounding elements such as automation, verification, model serving, and monitoring.
MLOps ultimately concerns itself with the question of how ML can bring value to an organization and the users of ML. Developing a model which can solve a problem well in a research setting is the first step but still far from the end goal. Only when the results of a model are actively consumed by (internal or external) users does it start to provide real value. To continue providing value it also needs to be monitored, re-trained, and updated when necessary.
Built on solid DevOps foundations
DevOps breaks down the silos of "development" teams (who want to push new features) and "operations" teams (who want stability). Rather than having a dedicated team of developers which write all the code for the application and then "throw it over a wall of confusion" to the operations team (Figure 4 top), a holistic team of DevOps engineers are responsible for both the development and the operations of the application (Figure 4 bottom).
There are several challenges which need to be addressed when MLOps is added on top of DevOps. For example, because data scientists will usually experiment with many models and sets of data, experiments need to be carefully tracked and versioned to maintain reproducibility. Model performance often decays over time and needs to be monitored meticulously. Of course, building a robust ML system also requires additional team skills which need to be developed and fostered.
Developing the blueprint for a digital highway
The Effective MLOps approach we propose at MLAB enables what are called the 4 Cs of MLOps (see this Google post and also our previous blog post): Continuous Integration (CI), Continuous Delivery (CD), Continuous Monitoring (CM), and Continuous Training (CT). Our mission at MLAB is to help people and organizations design, build and enable their Digital Highway for MLOps. In this blog post we introduce our blueprint for this digital highway, explain the purpose of the different components, and describe how they interact.
The blueprint shows a target picture. It includes many important elements which we will describe in detail below. Importantly, it is not set in stone and should be adapted to specific needs and the (current as well as target) maturity of the organization (see also our previous blog post on this topic). Our highway is also tool agnostic. It is not based on any specific solution as we believe tools should always be chosen based on the specific situation. Finally, we believe the blueprint can be helpful to companies of all sizes. Small, medium and large enterprises can use it as a basis to extract maximum value from their data and machine learning models.
The Machine Learning lifecycle
At a very high level, the MLOps lifecycle starts with data which is ingested and transformed, and then used to train machine learning models. The best model is then chosen and deployed to production where it runs as a service for other (user-facing) applications. New data is collected through user interactions which closes the loop. Code, data, model, and any other artifacts are always versioned and backed up. All steps in the lifecycle are monitored using dedicated observability solutions. In the following we walk through these stages of the MLOps lifecycle and explain the various components of our blueprint in more detail. (If you want to know more about an illustrative example of a Machine Learning development lifecycle for healthcare have a look at our previous blog post.)
Data pipeline
Data is the "oil of the 21st century" (see also this Medium story). While you might not (fully) agree with that statement, it is clear that data is critical when building machine learning models. Indeed, it can be more beneficial to improve models through data and feature engineering rather than model engineering (e.g., see the Data-centric AI approach). Many different types and sizes of data are used and so every data pipeline will need to be adapted to fit the use case. Nevertheless, a few common steps can be identified. These steps are similar regardless of whether streaming or batch processing is used. Data needs to be extracted from internal (production) and external data sources and the relevant data needs to be selected. Data augmentation could be used here or at a later stage to increase the amount of data if appropriate. The data might be pre-processed and transformed into a different format. For example, for natural language processing tasks we might want to perform some text pre-processing such as tokenization. If sets of data stem from different sources, we will want to combine them. Ideally, defined schemas for input data are checked; as, for example, the height of a human adult should be a floating-point number between 30 and 300 if it is encoded as centimeters. Violations must be detected, logged, and might trigger alarms. Features relevant for model development can be extracted and saved in dedicated feature stores. For each step in the pipeline, input and output data should be stored and versioned in one or more artifact stores at which we will have a closer look below.
Data quality is important and needs to be checked rather than assumed. Quality gates can be used to make sure certain characteristics of the data hold. We can check distributional statistics and if data and features (approximately) follow the expected distribution (normal, exponential, uniform, ...). We might want to compare distributions and size of the current data to those of previous data and warn if unexpected mismatches occur. Data schemas can be checked again if, for example, we transformed our height data from centimeters into meters and now expect numerical values between 0.3 and 3.
Model pipeline
Like data pipelines, model pipelines will vary a lot depending on the exact project, but generally include a few common steps. The model pipeline starts by loading the relevant data from storage. Any model-specific transformations of the data are applied, and features can be selected and standardized as needed. A model is trained, including steps such as hyperparameter optimization, according to the specifications of the data scientist or the AutoML system. For large models this often requires additional compute resources to be spun up on demand. The trained model is then evaluated and validated. Various performance metrics are calculated (on hold-out data) and compared to those of previous models. If the newly trained model is deemed an improvement over the current one, it is selected as potential artifact for deployment. Before release, we need to make sure it passes relevant quality gates. For example, we should test how missing or invalid data is handled, estimate the performance on various slices of the data, and measure the time it takes for the model to perform inference.
Application pipeline and release strategy
Many companies wanting to use ML within their system will already have application pipelines to deploy their non-ML (micro-)services. For example, a healthcare clinic might already have a booking system where patients can fill in an online form describing their issue in detail and will then be able to request a consultation with a specialist. The clinic now wants to use artificial intelligence to (1) filter out spam bookings, and (2) automatically extract relevant information from the patients’ descriptions to link relevant resources, estimate the urgency of the booking, or even automatically offer timeslots with an appropriate physician.
There are at least two common ways in which model serving is implemented within modern microservice architectures. For the first one the model is integrated into an existing application. It is loaded into memory and inference can therefore be very fast. This is a potentially simpler approach than the second one, but this also means that no other application will have direct access to the model. This tight coupling can be an appropriate strategy for some systems. The second common way is a microservice approach for which the model is deployed as a standalone service which other services can query through an exposed API. This introduces less coupling and means the model service and other applications can be changed independently but the approach introduces additional network latency and complexity.
With the application pipeline and model serving elements in our blueprint we aim to capture any model serving ways. The model can be directly included into the code of the existing service, or a new microservice can be created which exposes a simple API for requests. For example, it could accept text inputs and return a number between 0 and 1 representing the estimation of how positive the sentiment of the input was.
A common release strategy in today's IT world is the canary deployment, but blue/green or other deployments can also frequently be encountered. Staging / “dev” / QA environments, feature flags, and other tools should not be forgotten even if they are abstracted away in our blueprint.
Production infrastructure
We believe that for most companies a cloud strategy will be the future. Many of our concepts are developed with that in mind, and we work with many cloud-native tools. Cloud-based microservice architectures provide many benefits to our customers. Machine learning models, just as classical software applications, should be highly available, responsive, and fault-tolerant which typically means they will be replicated across multiple regions. Nevertheless, our digital highway for MLOps does not rely on a microservice architecture and can also be used as a blueprint for deployment within monolithic or hybrid architectures.
It is essential that not just the final model is deployed, but instead that data and model pipelines are deployed. We don't just want to run the pipeline once and then deploy the final model, but enable continuous training by deploying the pipelines. When new data is (with as little manual work as possible) ingested, all pipelines can run automatically, and an updated model can be released if it achieves better performance. Ultimately this would even open up the possibility of automatically deployed personalized models, e.g., a model that is only trained on the user's private data.
It is also crucially important that companies implement monitoring and observability for data and models in production (perhaps even more important than the monitoring of classical software) which we will address in the following section.
Observability and incident management
Observability for MLOps is an important topic, and we wrote a more detailed blog post about it here. In brief, we want to actively monitor the whole lifecycle of the machine learning project which means employing observability solutions so that any issues are detected (and even fixed) before they are noticed by (a substantial number of) customers. To address any incidents which may occur, we need to be able to efficiently push new versions of our code which includes a bug fix, trigger a rollback to the previous version, re-train the model, verify our data sets, scale our infrastructure, and perform many other incident responses. One good option to implement and manage non-functional requirements (NFRs) such as model performance which is continuously monitored is by applying a Site Reliability Engineering (SRE) methodology.
Site Reliability Engineering (SRE) for MLOps
The SRE approach is a way to manage NFRs of systems such as reliability, performance, availability, and latency. The implementation is based on Service Level Indicators (SLIs), Service Level Objectives (SLOs), and error budgets which are a way to handle the tradeoff between delivery speed and reliability. (For more information about these fundamental concepts have a look at some previous blog posts by our colleagues at Digital Architects Zurich: SRE Overview and Effective SRE.)
At MLAB we took the SRE concept and developed it further so that it can also be applied to MLOps. For example, we can use it to ensure an acceptable performance for a recommendation system. Look out for an upcoming blog post which will provide many more details about this topic. (Or, if you can't wait to discuss with us feel free to reach out!)
Code & artifact stores
Source control and artifact storage are important for traditional DevOps workflows and remain just as important for MLOps. “Versioning everything” is crucial for reproducibility and for allowing rollbacks. Collaboration also needs to be ensured through these version control systems. We want to keep track of code, build artifacts (e.g., Docker images), test results, and any other files or information produced during the run of our pipelines. MLOps adds two vitally important dimensions which will need to be carefully tracked and versioned: the data and the model.
Data needs to be stored in its various forms (raw data, processed data, feature store, …) and it needs to be discoverable and accessible (with appropriate access controls). Similarly, trained models need to be accessible as artifacts ready for deployment, and for long-running training pipelines we want to save checkpoints of the model. Meta-data, for example, in the form of "experiments", needs to be saved for every model run so that it is always clear which exact version of the code and data produced the model.
AIOps
AI-driven IT operations are becoming more and more important for mature DevOps and SRE-based workflows. It includes intelligent observability solutions which can help detect anomalies, group together alerts, find root causes of incidents, correlate data, automate rollbacks, and many other things (look out for a future blog post which will dive deeper into this!). All these concepts remain relevant for MLOps which again adds additional dimensions (data + model) that will have to be included.
Testing and quality gates
Quality assurance through testing and gates is an established concept in classical software development but still in its infancy in the field of MLOps. Nevertheless, at MLAB we are already thinking deeply about these important issues and will describe our thoughts in detail in an upcoming blog post on this topic!
Manual exploration and experimentation
In most cases, ideas for new ML models will start on a small scale. Exploratory data analysis will be performed and initial proof of concept (POC) ML models will be trained. Initial steps might be performed on researchers' laptops or on separate cloud instances not connected to production. Nevertheless, it is good to have fully functioning (even if rudimentary) pipelines available as soon as possible so the whole MLOps system can be improved iteratively.
Manual exploration and experimentation will always remain relevant, and it is important for the system to facilitate this work of data scientists. We want frictionless transitions between exploratory analyses, POCs, and fully deployed models. For example, as many data scientists commonly work with notebooks there should be a straightforward path from notebook to pipeline integration. As another example, "shadow models" can be deployed to production alongside the currently running model. They are asked to make the same predictions as the live model so that the performance can be evaluated.
Roles and cross-functional collaboration in MLOps
One of the big challenges facing companies is that successful digital transformation is arduous and requires many skills and capabilities such as data engineering, ML engineering, data science, DevOps practices, domain & business experts, product owners, and SREs. Together, the team should cover software and model development, deployment, operations, monitoring, incident management, and many others. Our vision is to break down silos and enable a culture and operating model which foster cross-functional collaborations and skill sharing. We will come back to this in one of the following sections.
The pillars which complete the blueprint
The digital highway rests on 8 pillars which make up the foundation. We believe that these concepts are important and should be considered for any digital transformation.
- Cloud stack: We believe that most modern applications will be built on the cloud, following a “cloud-first” mindset.
- Infrastructure provisioning: The provisioning of infrastructure (in the cloud) should be elastic so that it can easily be scaled up or down depending on demand.
- Infrastructure & monitoring as code: Infrastructure and monitoring configurations should not require fiddling with graphical frontends, but instead be defined as code which also means they can be tracked and versioned.
- Audit & compliance: In many industries compliance with certain standards and regulations is mandatory. It is important to ensure the whole digital highway is always auditable.
- Application reliability architecture: Application developers should use best practices such as implementing resiliency patterns to ensure a reliable architecture.
- Data platform: A strategy for a data platform should be well-defined for the whole company, including the use of data lakes, data warehouses, and other structured or unstructured databases. Data should be versioned, classified, discoverable, accessible (with proper access control), shareable, and auditable across the whole company.
- Analytics architecture: A strategy for an analytics and machine learning architecture should be defined and implemented so that it can be used as basis for the digital highway.
- Explainable AI: We believe that explainability and interpretability are critically important concepts for Machine Learning systems in the real world. Many organizations do not just want black-box AI approaches which give no insight into why a model makes a certain prediction but instead want to be able to understand its inner workings. This is especially true when models are used to support important decisions in areas such as healthcare. (Look out also for our upcoming blog post on this topic of explainable AI!)
Our detailed blueprint
This completes our blueprint for the digital highway for MLOps and reliable and continuous machine learning delivery and operations which is shown in full detail in Figure 11.
Technology tools and solutions
One might wonder why we did not mention specific tools and solutions during the discussion of this blueprint. This is because at Machine Learning Architects Basel (MLAB) we believe that tools should not be the focus of a digital transformation. The strategy, capabilities, requirements and goals should be defined first and then tools can be analyzed and a set chosen to cover all relevant areas.
MLAB closely works with a number technology partners, but also remains independent and is continuously expanding its portfolio and benchmarking established as well as upcoming and innovative technologies.
Culture and operating model
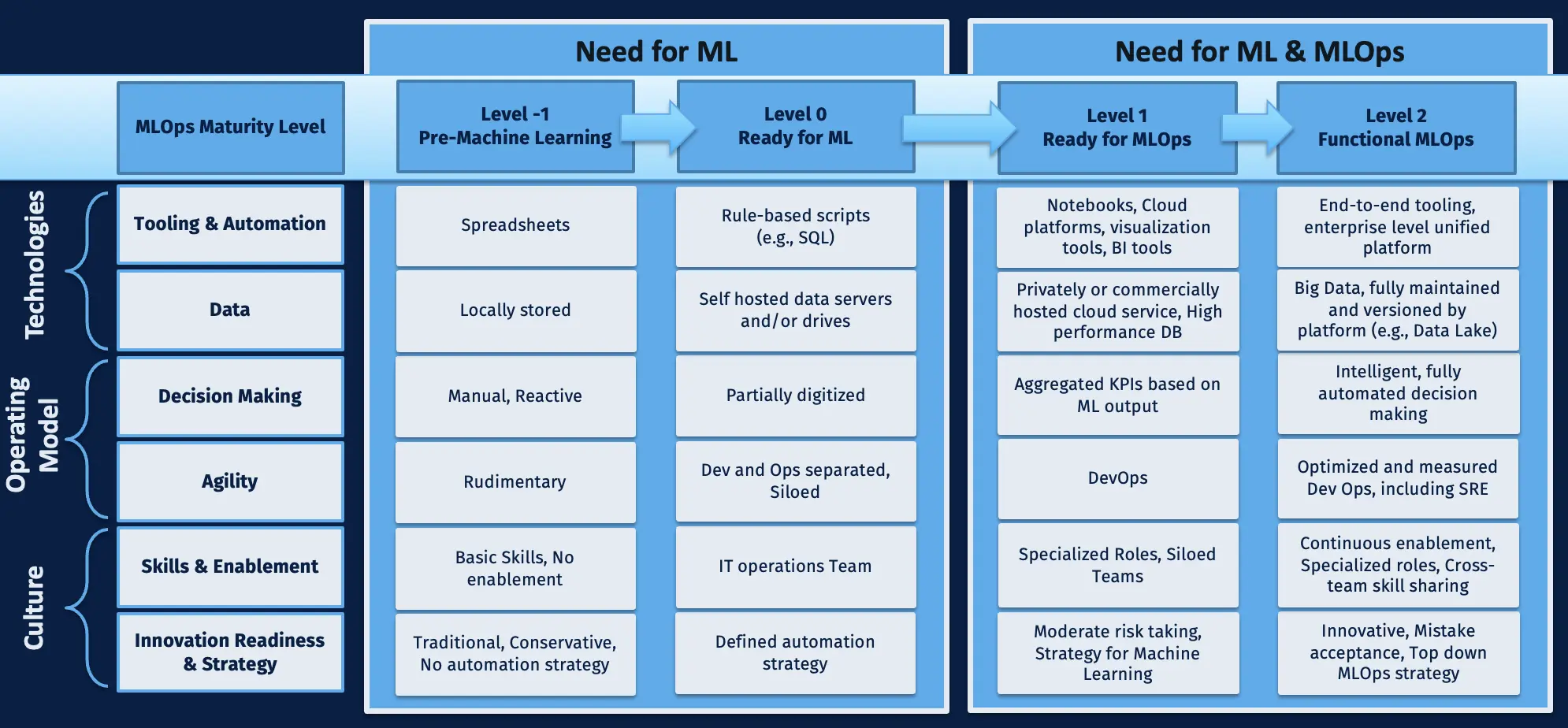
Last but not least, we want to emphasize that we believe that a digital transformation has the greatest chance of success if it goes hand in hand with a transformation of a company’s culture and operating model. There should be continuous enablement across the team, a holistic MLOps strategy which is agreed by all key participants, an acceptance of mistakes, and a mindset of continuous innovation. The operating model should include intelligent, automated decision-making, and an optimized DevOps and SRE approach. We described this in more detail in another one of our previous blog posts (see also Figure 12 below).
{kind=link}
Machine Learning Architects Basel
Machine Learning Architects Basel (MLAB) is part of the Swiss Digital Network (SDN) which has extensive knowledge and experience around DevOps, SRE, and AIOps regarding "classical" non-ML systems. In addition to our tried and tested effective SRE approach, we have also developed an effective MLOps approach and in this blog post we presented our blueprint for a digital highway for end-to-end machine learning and effective MLOps.
It includes data, model and application pipelines, observability, incident management, but also operating models, training and cultural transformation as fundamental components. No matter where you stand now, we at MLAB and SDN will be able to support you in your digital journey. Whether you are completely new to ML and want to "start right" or have extensive experience but are looking to improve one aspect such as observability, we will be able to advise you.
If you are interested in learning more about how MLAB can help your business generate sustainable value by building and running reliable machine learning solutions, and supporting the implementation of a digital highway for your company, please do not hesitate to get in touch.