
Introduction
In the rapidly evolving world of AI, Large Language Models (LLMs) have become essential tools for a wide range of applications, from natural language processing to content generation. However, deploying and running LLMs in production can be complex and challenging, especially when ensuring reliability, scalability, and security. In this tutorial, we will walk you through setting up your LLMs in production using a robust, cloud-native stack built on AWS, Kubernetes, and other key open-source tools.
The following tutorial is part of our blog post and webinar series on scalable and reliable generative AI solutions and LLM(Ops) implementations, powered by our Digital Highway approach.
For example, the preceding blog post provides a theoretical introduction to reliably implementing LLMs and RAG.
Prerequisites
Before diving into the tutorial, you should have a basic understanding of the following.
AWS services (VPC, EKS, IAM, etc.)
During our journey, we will use AWS as cloud provider. There are many commercial cloud providers where you can deploy your LLM model in the same way as we will do in this technical blog post; it is up to you which provider you want to use.
Kubernetes concepts and management
We use Kubernetes to scale our application. Other tools similar to Kubernetes include Docker Swarm and Apache Mesos, which also provide container orchestration and management capabilities. The advantage of using Kubernetes is its robust scalability and extensive ecosystem, which enable seamless application deployment, scaling, and management.
Karpenter for automated resource scaling
Kubernetes Karpenter is an open-source node provisioning system that automatically scales clusters by launching the right amount of compute resources based on application demand. For LLMs, it can allocate additional resources for computationally intensive tasks like training and inference.
AWS CDK (Cloud Development Kit) for Infrastructure as Code
AWS has a powerful CDK framework, which ables us to define and manage our infrastructure as a Python code.
HelmChart
HelmChart is a set of YAML manifests and templates that is used to configure Kubernetes resources.
Note
This stack is an example demonstrating how you can set up and manage your infrastructure for deploying large language models (LLMs) on AWS. While this tutorial focuses on AWS-specific tools and approaches, similar infrastructure can be implemented on other cloud platforms like Google Cloud Platform (GCP) or Microsoft Azure. The key takeaway is that cloud-agnostic capabilities like Kubernetes, Infrastructure as Code (IaC), and CI/CD pipelines are universal, enabling you to adapt and deploy similar stacks across various environments. Applying the CI/CD best practices is crucial for efficiently managing this stack. This includes automating the deployment process, implementing proper version control, and continuously integrating and testing new code changes.
Overview of the Stack
This tutorial deploys a comprehensive stack that includes:
- MLABAIStack: Core AI stack for deploying and running LLMs.
- KarpenterStack: Resource autoscaler based on node claims.
- CertManagerStack: Manages SSL/TLS certificates for secure communication.
- HuggingfaceStack: Integrates Hugging Face models and datasets.
- MLflowStack: Manages ML experiments, tracking, and model versioning.
- OTelStack: Enables observability and tracing with OpenTelemetry.
- TeardownStack: Simplifies resource cleanup to manage costs and resources effectively.
- HelmChart: Defines, installs, and manages applications using a templated YAML files.
These stacks run on an Amazon EKS cluster, providing a scalable and resilient environment for software workloads. During the deployment, we use HelmCharts templated YAML files, which streamline the process by packaging all necessary resources (like deployment configs, services, etc.).
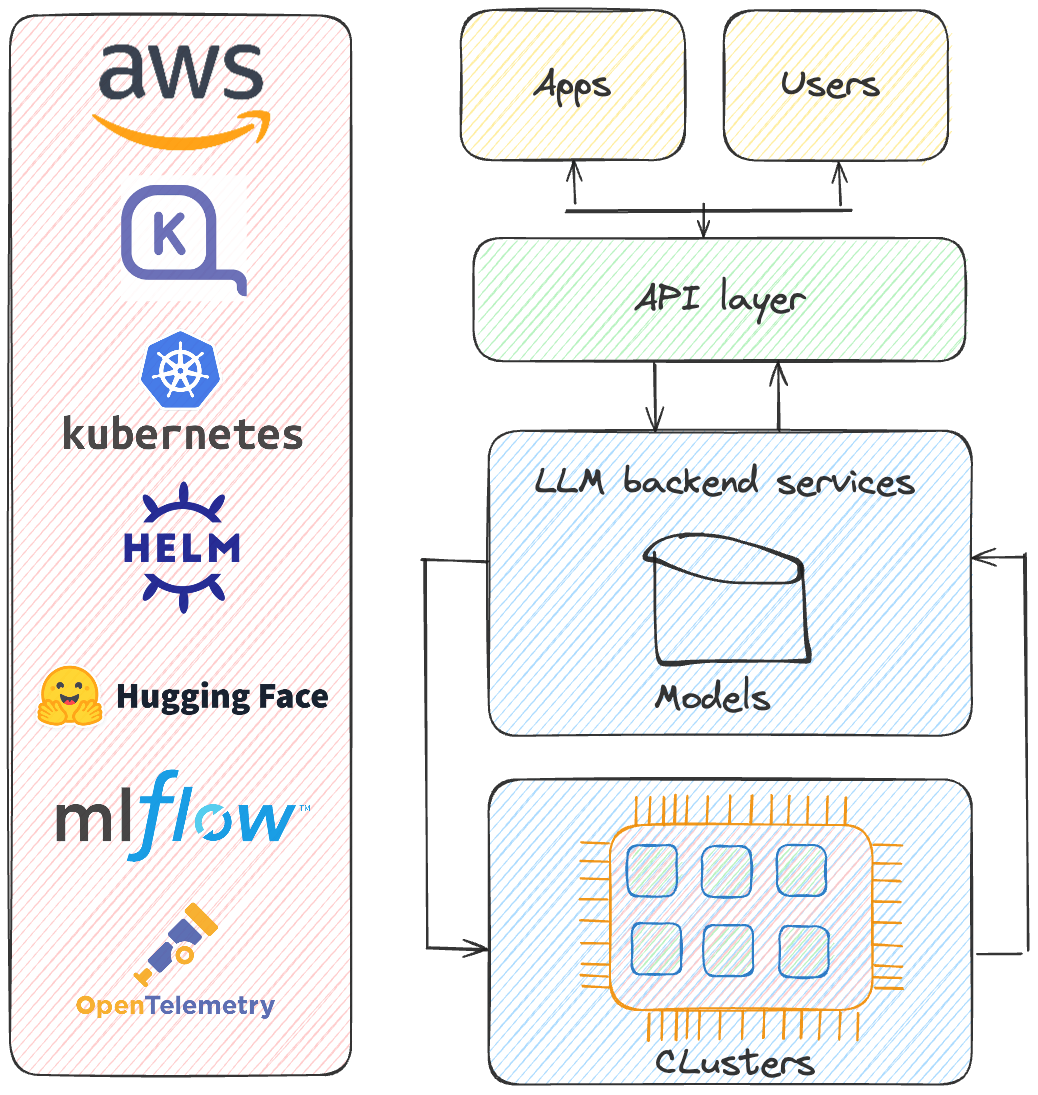
Step-by-Step Tutorial
Step 1: Setting Up the VPC and EKS Cluster
In the first step, we set up the underlying infrastructure to host the LLM model. This includes creating a Virtual Private Cloud (VPC) and an Amazon EKS cluster. The VPCStack creates a VPC with subnets, security groups, and routing tables, while the EKSStack provisions the EKS cluster within this VPC.
Step 2: Deploying the Core MLABAIStack Stack
Amazon Elastic Kubernetes Service (EKS) is a managed Kubernetes service that simplifies deploying, managing, and scaling containerized applications using Kubernetes. It abstracts much of the complexity involved in managing Kubernetes clusters, allowing us to focus on our application rather than the underlying infrastructure.
EKS provides the following capabilities:
- NVIDIA Device Plugin: Utilize NVIDIA GPUs in the EKS cluster.
- EBS CSI Controller: Configure Amazon EBS CSI for proivison and manage EBS volumes.
- AWS ALB Controller: Manages the provisioning and lifecycle of ALBs, providing external access to LLM models.
- External DNS Controller: Automatically manages and updates DNS records when Kubernetes services are created, modified, or deleted.
- EKS Pod Identity: Providing fine-grained access control for workloads running in the cluster.
- SSL Certificate: Creates SSL certificates for various subdomains.
Container Orchestration: EKS manages the deployment, scaling, and operation of containerized applications. For running LLMs, this means that we can deploy our models, and Kubernetes will handle scaling and load balancing.
Integration with EC2: EKS can leverage EC2 instances to run our applications. We use different EC2 instance types based on our needs, including those optimized for high-performance computing tasks.
Amazon Elastic Compute Cloud (EC2) provides scalable computing capacity in the cloud. EC2 instances play a critical role in LLM deployments, particularly when running large models that require substantial GPU resources and memory.
- Instance Types: EC2 offers various instance types, including ones optimized for compute (e.g., C5 instances) or memory (e.g., G5 instances), which are essential for running large models efficiently.
- Scalability: We can scale our EC2 instances up or down based on our workload using Karpenter.
For LLMs, we need powerful GPU instances for efficient model inference and training. We use the G5 EC2 instance type with the following features:
2nd generation AMD EPYC processors (AMD EPYC 7R32)
Up to 8 NVIDIA A10G Tensor Core GPUs
Up to 100 Gbps of network bandwidth
Up to 7.6 TB of local NVMe local storage
For computing, we deploy a C6i instance that is optimized for applications that require a significant amount of computational power, such as high-performance computing. The MLABAIStack is the heart of our deployment. It sets up key infrastructure components and services in the EKS cluster to support ML workloads, ensuring secure, scalable, and efficient operations.
Step3: Implementation of EKS node autoscaler with Karpenter
In scenarios where LLM must operate in a high-throughput environment, we implement Karpenter for autoscaling the underlying resources based on demand. Karpenter receives a node claim, which signals that the cluster needs additional capacity. This claim is generated when the Kubernetes cluster scheduler can not find a node to place a pod. In this scenario, the pod is in a pending state. Karpenter resolves this by calculating the most cost-effective, right-sized resources that satisfy the pod's requirements. Karpenter sends a request to AWS to provision the necessary EC2 instance with the right resources. Karpenter is all about just-in-time infrastructure. It dynamically reacts to the cluster’s needs, intelligently provisioning and terminating nodes based on real-time demand and custom policies we have defined in our provisioner. This makes it highly suitable for our dynamic LLM environment where the resource profile can change rapidly and resource costs are high.
Step 4: Securing Your Application with CertManager
Security is crucial for any production environment. The CertManagerStack manages SSL/TLS certificates, ensuring all communication between our services is encrypted.
Step 5: Integrating Hugging Face Models
Hugging Face provides a vast repository of pre-trained models that can be easily deployed and fine-tuned. HuggingfaceStack will integrate these models into our environment.
Hugging Face Transformers: Hugging Face is a leading Natural Language Processing (NLP) platform that offers a vast repository of pre-trained models, including various Large Language Models (LLMs) like GPT, Llama3, and Bert. The Hugging Face transformers library provides tools to easily integrate these models into your applications, handle model training, and perform inference. It supports framework interoperability between PyTorch, TensorFlow, and JAX. This provides us with the flexibility to use different frameworks at each stage of a model’s lifecycle, allowing us to train a model in one framework and load it for inference in another with a few lines of code.
from transformers import AutoModelForObjectDetection
model = AutoModelForObjectDetection.from_pretrained(
"hustvl/yolos-base",
attn_implementation="sdpa",
torch_dtype=torch.float16
)
Additionally, Hugging Face provides additional features to speed up production deployment.
Model Hub: The Hugging Face Model Hub hosts thousands of pre-trained models. We can leverage these models for various NLP tasks without needing to train them from scratch.
Inference API: Provides a simple way to interact with models hosted on Hugging Face. This API can be used for quick prototyping and testing. This stack integrates Hugging Face transformers and model hubs with our EKS cluster, making it easy to deploy, manage, and scale LLMs.
In this section, we are sharing the full implementation of the HuggingfaceStack:
from aws_cdk import (
Tags,
Stack,
aws_eks as eks,
aws_ssm as ssm,
)
from constructs import Construct
import yaml
class HuggingfaceStack(Stack):
def __init__(self, scope: Construct, construct_id: str, cluster, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# deploy helm chart
with open('./deployment/huggingface_stack_values.yaml', 'r') as yaml_file:
yaml_content = yaml.safe_load(yaml_file)
hf_ro_token = ssm.StringParameter.from_string_parameter_attributes(
self, 'hfReadOnlyToken',
parameter_name='/mlab-ai/hf_ro_token',
# Optionally specify the version of the parameter
version=1
).string_value
yaml_content['model']['hf_token'] = hf_ro_token
yaml_content['extraEnvVars'][0]['value'] = hf_ro_token
eks.HelmChart(
self, "HFHelmChart",
cluster=cluster,
chart="huggingface-model",
release="mlab-ai",
repository="oci://registry-1.docker.io/shalb/huggingface-model",
values=yaml_content,
version="0.2.1"
)
Tags.of(self).add('Project', 'mlab_ai_rag')
Tags.of(self).add('AutoDelete', 'true')
Tags.of(self).add('Order', '3')
Step 6: Experiment Tracking with MLflow
MLflow is a powerful tool for tracking experiments, managing models, and monitoring performance. The MLflowStack integrates MLflow into our deployment. With MLflow, we can apply the MLOps best practices to our project, such as evaluating and monitoring LLMs and RAGs. It provides automated metadata tracking and management for model metrics, artifacts, and LLM interactions. MLflow automatically logs prompts, responses, and associated metadata, enabling users to visualize and manage LLM interactions while monitoring and optimizing prompt engineering and model performance.
Step 7: Enhancing Observability with OTelStack
Monitoring and tracing performance is essential to ensure your LLMs runs as expected. The OTelStack adds observability through OpenTelemetry, enabling detailed logging and tracing for monitoring LLM operations. In the context of LLMs, OpenTelemetry helps us track and measure model inference performance and behavior, ensuring that latency, errors, and resource utilization are monitored effectively. It provides detailed insights into how models are being used and how they perform under different loads. Check out this blog post, where we explain the concepts of monitoring and observability in more detail. Moreover, watch out for our forthcoming blog post, which will illustrate a technical implementation of observability for data, ML, and LLM systems. Sign up for our newsletter, or follow us on Linkedin to stay tuned!
Step 8: Managing Resources with TeardownStack
Finally, our TeardownStack simplified resource management by automating the cleanup of resources when they are no longer needed. It uses AWS CloudFormation Event Rule, which kicks off an AWS Lambda function for tearing down the complete stacks and all their resources.
Setting Up Dependencies
The order in which these stacks are set up is crucial for ensuring that dependencies are correctly managed. For instance, CertManagerStack depends on the EKS cluster, and HuggingfaceStack and MLflowStack depend on the MLABAIStack.
eks_stack.add_dependency(karpenter_stack)
eks_stack.add_dependency(vpc_stack)
mlab_ai_stack.add_dependency(eks_stack)
karpenter_controller_stack.add_dependency(eks_stack)
cert_manager_stack.add_dependency(mlab_ai_stack)
huggingface_stack.add_dependency(mlab_ai_stack)
otel_stack.add_dependency(mlab_ai_stack)
mlflow_stack.add_dependency(mlab_ai_stack)
auto_destroy_stack.add_dependency(mlab_ai_stack)
Conclusion
Deploying and running LLMs in production involves integrating multiple components, each vital to ensuring a reliable, scalable, and secure environment. By completing this tutorial, you should have gained a clear understanding of how to manage and deploy LLMs effectively. Ensure you follow best practices for security, monitoring, and scaling as you deploy your models. With the right stack, you can focus on innovating with LLMs while relying on a solid and dependable infrastructure. If you have questions or want to learn more about this guide or topic, please contact us!
Machine Learning Architects Basel
Machine Learning Architects Basel (MLAB) is a member of the Swiss Digital Network (SDN). With several years of experience and a team of experts, we support our customers in confidently deploying, scaling, and operating their data and AI products beyond the pilot and prototype stages.
Check out our guides: